A Spring 2026 course connecting the historical foundations of vision with modern deep learning,
transformers, and hands-on project work.
Abstract
Machine learning has profoundly changed computer vision, but the field's current methods build on a long
history of image formation, geometry, perception, recognition, and representation learning. This lecture
takes a holistic view of the task of vision.
Lectures and tutorials are accompanied by bi-weekly quizzes and project work. Assessment combines
bi-weekly quizzes, the project, and the final exam.
FormatLectures, tutorials, bi-weekly quizzes, project work, and final exam.
BibliographyFoundations of Computer Vision, Antonio Torralba, Phillip Isola, William T. Freeman, MIT Press, 2024.
ProgramsMSc Artificial Intelligence, MSc Computational Science, MSc Informatics, and Faculty of Informatics PhD students.
Student Project Ideas
Project proposals live here so classmates can quickly scan possible directions, compare ideas, and submit
additions by pull request.
Example project idea
Scene understanding, geometry, foundation models
Semantic Change Maps from Everyday Walks
Can a short phone video reveal how a campus route changes over time? This project combines monocular
depth, semantic segmentation, and feature matching to align walks recorded on different days, then
highlights moved objects, blocked paths, or new scene elements. The result would be a small visual demo
that connects 3D reasoning, human attention, and practical scene understanding for urban navigation.
Group J
Self-supervised video representations, foundation models, anomaly detection
Can V-JEPA read ECG?
Can V-JEPA learn meaningful representations for ECG-based arrhythmia detection? In this project, we investigate whether a V-JEPA encoder, originally designed for video understanding, can capture clinically relevant patterns from ECG signals. We transform ECG recordings into video-like inputs and use the pretrained V-JEPA encoder to generate latent representations. These representations are then evaluated by training a range of downstream predictors for arrhythmia classification. By comparing performance across predictors, we assess the quality and transferability of V-JEPA features for cardiac signal analysis.
This project explores visual product search for marketplace applications, where users can search for visually similar
items using a single photo. I build a retrieval pipeline based on vision-language embeddings, object segmentation,
category-aware routing, and color-aware reranking to improve search quality for fashion and marketplace-style product
images. The final system is demonstrated in an Android app that performs on-device image-based retrieval over a local
product catalog.
Aegis Rider is a motorcycle AR demo that simulates a smart-helmet riding experience.
It takes a first-person riding video, detects surrounding road users, estimates potential collision risks,
and overlays a HUD directly onto the video. The system also includes radar-style awareness visualization
and basic navigation features, providing riders with real-time environmental and directional information
in an intuitive AR interface.
Group C
Video Search, Segmentation, Foundation Models
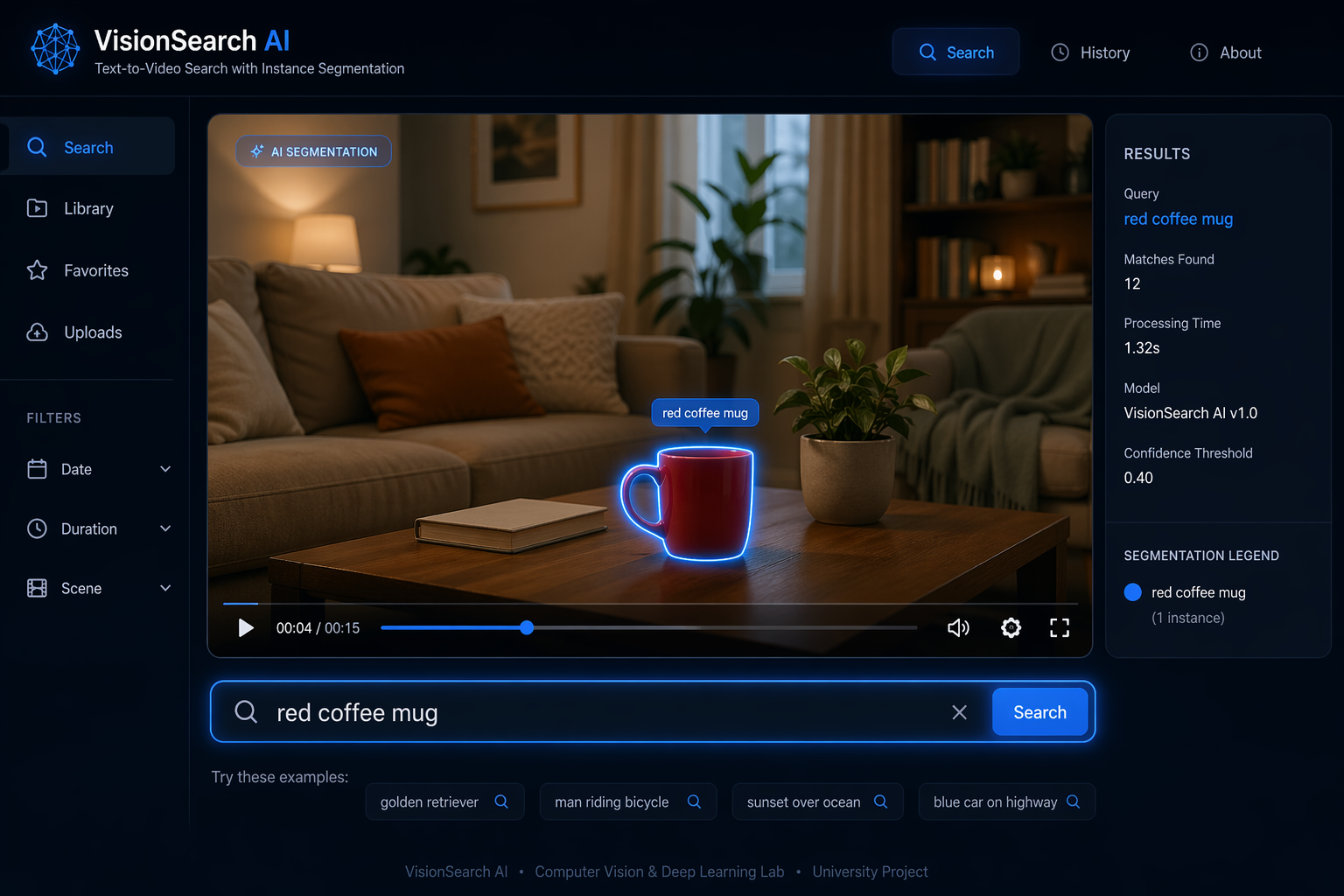
SemanticSpot: "Ctrl+F" for Videos
Ever wanted to find a specific object or action in a long video without scrubbing through it manually? SemanticSpot is an interactive web app that lets you search videos using natural language. You can simply type a query like "the person wearing a blue hat" or "the red coffee mug". Behind the scenes, the app uses CLIP to instantly locate the exact timestamp where your search appears, and SAM (Segment Anything) to dynamically track and highlight the object on the screen. It’s a smart, zero-shot visual search engine combined with automatic segmentation!
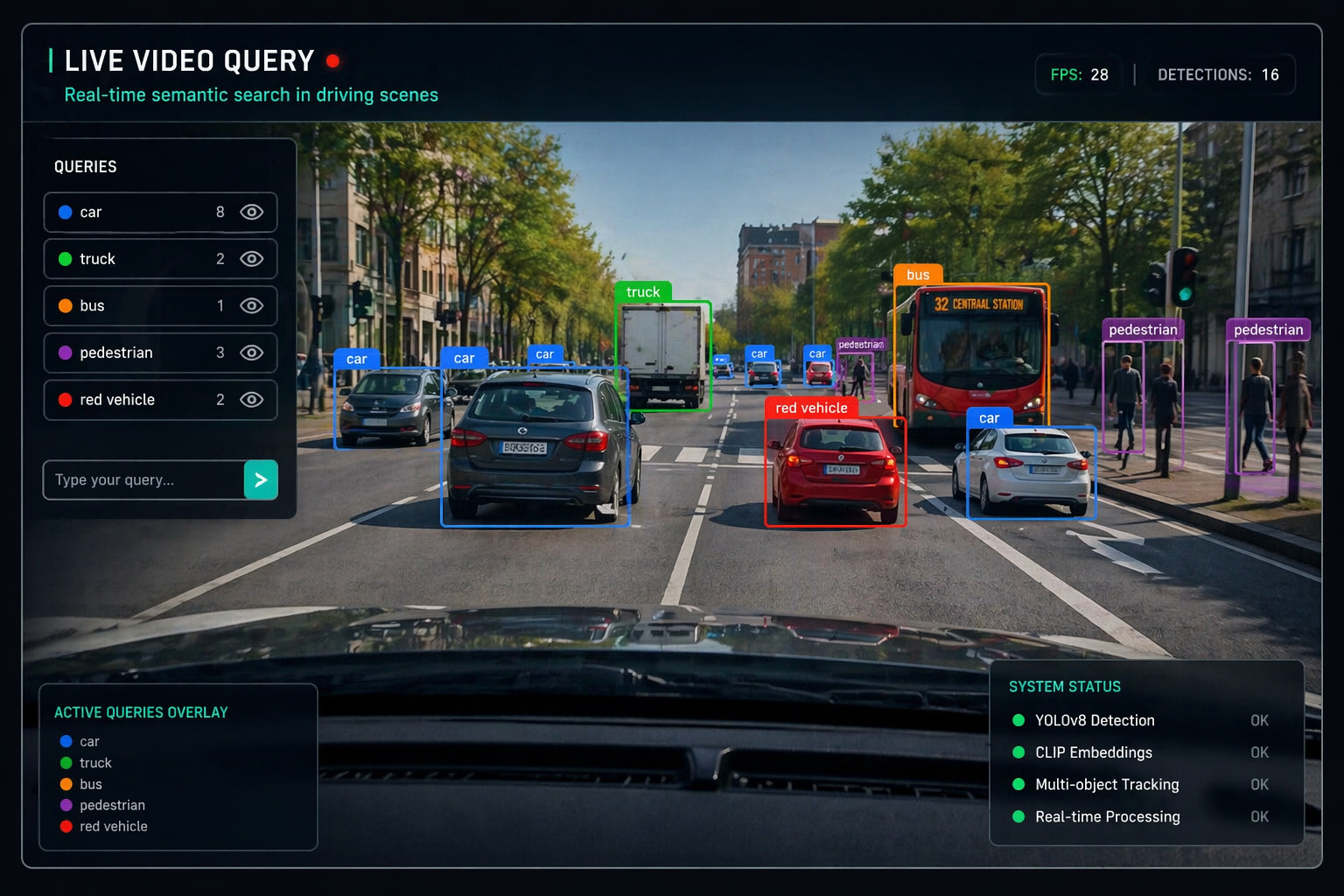
This project transforms a driving scene taken from a dashcam into an interface where users can type natural language queries such as "a classic new york taxi", "a work truck" and "a pedestrian" and see matching objects highlighted and tracked in real time.
The demo emphasizes open-vocabulary capabilities: queries can written in natural language, multiple concepts can be explored simultaneously, and each query is visualized with distinct colors for clarity.
Rather than focusing purely on detection, the project also adds a way to detect whenever a pedestrian is actively crossing the road, marking it in red to highlight it. Moreover a small detector runs in parallel to detect traffic signs, also responding to natural language queries given by the user, like "no parking sign" or "one-way sign".
Group M
Emotion recognition, deep learning, CNN-RNN
Facial Expression Recognition with Hybrid Models
Can a model reliably read human emotions from a single image? This project explores facial expression recognition by classifying faces into categories such as happiness, sadness, anger, and surprise. We build a small interactive demo that visualizes predicted emotions on input images.
To achieve this, we combine CNNs for spatial feature extraction with RNNs to capture temporal patterns, comparing pretrained models (MobileNetV2, InceptionV3) with a custom CNN-RNN trained from scratch on FER2013 and CK+ datasets.
The project focuses on evaluating performance, robustness, and how transfer learning influences emotion recognition across different data conditions.
Group O
Prompted segmentation, motion tracking, event detection, video highlights
Behaviour Lens
What if a video highlight came with the evidence behind it? Behaviour Lens takes a video and a text prompt, uses SAM3 to segment the requested object in sampled frames, and turns those detections into trajectories, velocities, timestamps, masks, overlays, and auditable CSV outputs.
The goal is to combine modern segmentation models (such as SAM) with classical computer vision techniques. Segmentation serves as a strong perception layer, while event detection is driven by motion-based features such as trajectories, velocity, and frequency analysis, along with lightweight reasoning.
The system follows a modular design, consisting of a general perception and feature extraction pipeline combined with task-specific event detection modules.
The system is primarily designed for human action detection (e.g., waving, raising a hand, standing up). As an extension, it can also handle simple sports scenarios, such as tracking a ball moving toward or crossing a goal, demonstrating its ability to generalize to multi-object interactions.
Open-Vocabulary Object Tracking with Grounding DINO, SAM 2 and CLIP
We present an open-vocabulary object tracking system that enables users to search, segment, and track arbitrary objects in images and videos using natural language queries.
Our pipeline combines Grounding DINO for text-conditioned object detection, CLIP for semantic verification, and SAM 2 for segmentation and temporal tracking.
The system supports interactive querying through a Gradio web interface and demonstrates how modern vision foundation models can be integrated into a unified visual understanding pipeline.
Group F
Monocular depth estimation, hand tracking, augmented reality, human-computer interaction
Air Instrument: Depth-Aware Virtual Music Placement
Air Instrument explores how a normal webcam can turn a room into an interactive musical stage. The system first
estimates scene depth using Depth Anything V2, detects candidate floor or surface regions, and lets users place
virtual instruments into available 3D space through hand gestures. Once instruments are placed, a playing mode uses
MediaPipe hand tracking to control expressive parameters such as pitch and volume without touching any physical
device.
The project combines monocular depth estimation, spatial reasoning, gesture recognition, and augmented reality
rendering into a live demo. Our goal is to study how depth-aware scene understanding can support natural interaction:
where can an object be placed, how large should it appear, and how can the user control it through movement?
Got a clue? ImageDetective can find the picture. Describe what you’re looking for, upload an image, or search by visual details. ImageDetective connects text and images through foundation models, combining global semantic search with patch-level matching for smarter and more explainable retrieval.
We will propose a vision language retrieval system to implement bidirectional search between images and natural language. With CLIP, we will map both modalities into a share embedding space, a image could be retrieved with FAISS indexing. Perhaps the accurary should be improved, further approach is using a SAM3 for text guided semantic segmentation and enable patch level matching.
Group I
Structure from Motion, 3D reconstruction, mobile robots
One video, a 3D reconstruction of civil infrastructure
Structure from Motion (SfM) is one of the most widely used techniques for reconstructing
objects and scenes from images or video. This project aims to test hand-crafted
Structure-from-Motion algorithms available in Colmap for reconstructing 3D environments
characterized by poor illumination, using frames captured from a limited linear camera
movements. The objective is to evaluate the limitations and accuracy of state-of-the-art
methods in challenging, hard-to-reconstruct environments.
Group A
Gesture detection, tracking
Real time hand gesture detection: from rock paper scissors to sign interpretation
This project focuses on building a computer vision system capable of recognizing a variety of hand signs and gestures captured by a static camera.
The core goal is to develop a robust gesture recognition pipeline that can distinguish between different hand configurations in real time.
As a proof-of-concept, the system will be integrated into the game of rock-paper-scissors, where it detects each player's gesture and determines the outcome of each round.
The final result will be an interactive demo showcasing accurate and responsive hand gesture recognition in a playful, real-world scenario.
Group P
Action recognition, video understanding, self-supervised embeddings
From Raw Footage to Recipe: Extracting Cooking Steps from Egocentric Video
This project builds a system that watches egocentric cooking videos and automatically extracts the sequence of cooking actions performed, with the goal of reconstructing a recipe from raw footage alone.
Because most frames in a cooking video are irrelevant, the pipeline first applies a relevance classifier to filter out background activity, then routes the remaining clips through an RNN-based action classifier that identifies steps such as cutting, peeling, and boiling.
Video representations are produced by V-JEPA 2, which encodes each video as a sequence of 64-frame block embeddings without requiring labeled pretraining data.
The result is an end-to-end pipeline that turns an unstructured kitchen video into a structured, step-by-step recipe.
Real-Time Whiteboard Transcription with Temporal Ledger
When a professor is at the board, you have two choices, pay attention, or copy. You can't really do both at the same time.
We wanted to eliminate that trade-off. Our system transcribes in real time what the professor writes, so the student is free to just listen and understand.
The pipeline captures the full evolution of whiteboard content across a lecture, every correction and erasure included, and synthesises it into structured Markdown output.
Group V
Video understanding, vision-language models, action captioning
Action/Event-Focused Captioning: A Three-Model Comparison
This project explores how pretrained image-captioning models can be adapted to produce short action-focused captions for video activity timelines. Instead of generating long descriptive captions, we fine-tune BLIP, ViT-GPT2, and Microsoft GIT on COCO action captions so that the models output compact labels such as “person walking” or “coffee being poured.”
For video inference, frames are sampled over time, captioned by the fine-tuned models, and de-duplicated into a simple activity timeline. The project compares original and fine-tuned models using BLEU-1, BLEU-2, METEOR, and ROUGE-L, and analyzes whether architecture choice still matters after all models are adapted to the same action-caption task.